
Why We Hardcode the DAG for B2B Approval Agents
By wGrow Project Team ·
The Failure Condition
Route a $500,000 purchase order to the wrong department head because of a hallucination, and the CFO doesn’t care about your prompt engineering. She cares that the wire was delayed three weeks and the vendor relationship is now damaged. The audit committee cares that there’s no explainable log of why the agent made that routing decision. The ISO auditor cares that the approval step was silently skipped.
That failure mode is real. In early internal testing of a procurement agent, we let the LLM reason about where documents should go next. It routed documents inconsistently before any payment workflow went live, so we redesigned the architecture before deployment.
The fix is not clever prompting. It is classical computer science.
Parsing is Probabilistic. Routing is Deterministic.
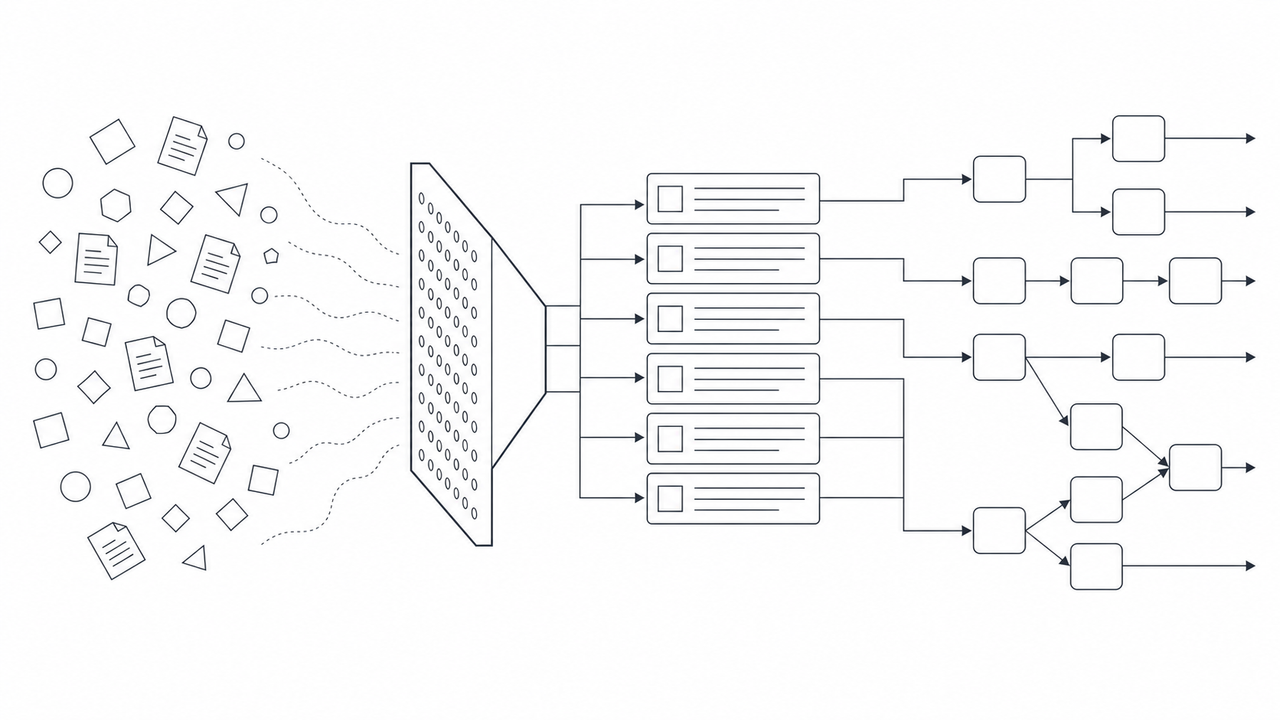
In every enterprise agent build, there’s one architectural decision that matters more than the rest: where the LLM’s authority ends.
LLMs are probabilistic engines, exceptional at one task: extracting structured signal from unstructured chaos. A scanned invoice with a rotated table, a non-standard vendor header, and handwritten annotations — a classical OCR template will fail. An LLM can often turn that payload into a structured candidate JSON object with vendor name, line items, subtotal, and tax amount. Validation decides whether that candidate is usable.
Workflow routing is a different job entirely. It is deterministic by requirement — a hardcoded set of rules, explicit state transitions, zero tolerance for probabilistic drift. We never ask an LLM, “Where should this document go next?” We ask it, “Extract the vendor name, subtotal, and tax amount as a valid JSON object matching this schema.” Once we have that structured output, a Python if/else block and a directed acyclic graph (DAG) take over. The LLM’s involvement ends at the handoff boundary.
This boundary is not a limitation. It is the design.
Confining the Model: The WaterDoctor Invoice Module
WaterDoctor is a deep-tech water treatment company we work with closely. Their procurement team processes invoices from dozens of vendors — chemical suppliers, equipment manufacturers, service contractors. The formats are a mess. Some vendors send PDFs with embedded tables. Others send scanned handwritten receipts. A few send invoices in formats that appear to be from the mid-nineties.
Classical OCR templates can’t handle this variance. We deployed an LLM node specifically to solve the parsing problem. The model reads the raw invoice payload and outputs a strict Pydantic model: InvoiceDocument with typed fields for vendor ID, issue date, line items (each a LineItem with description, quantity, unit price, and tax code), subtotal, tax total, and grand total. The schema is enforced. If the model output fails validation, the job fails and routes to a human exception queue. It does not retry autonomously.
That is where the agent’s freedom ends.
The verified InvoiceDocument object is handed to a deterministic state machine. The state machine checks the vendor ID against an approved vendor database, validates the tax codes against the Singapore GST schedule, compares the grand total against the purchase order it was issued against, and routes the payload to the correct finance queue based on amount thresholds and cost centre codes. The LLM has zero visibility into this routing phase. It cannot trigger the payment API. It cannot decide to skip the manager review step because the amount looks small.
We built the rails. The LLM powers one segment of the train.
Passing the ISO 27001 Audit
A regional logistics client — mid-sized freight forwarder, Southeast Asia operations — came with a harder constraint on top: auditability for every approval action under their ISO 27001 control set.
For our ISO 27001 audit evidence, every approval action and state transition had to be logged, attributable to an identity, and replayable for inspection. The auditor did not need the agent’s reasoning chain; they needed control evidence. An autonomous agent that dynamically skips a required manager approval step is not a harmless implementation detail. It is audit evidence that the control is not operating as designed.
We used LangGraph to construct a fixed, unskippable DAG. The nodes are explicit: DRAFT, MANAGER_REVIEW, DIRECTOR_APPROVAL, PO_GENERATION, COMPLETED. The edges between those nodes are hardcoded Python. There is no conditional branch the LLM controls. The only way to advance from MANAGER_REVIEW to DIRECTOR_APPROVAL is if the manager’s approval action is recorded in state and validated by the transition function. A prompt injection attempt embedded in the invoice body cannot change the routing graph. A model update cannot change it either.
The LLM exists in exactly two nodes. In DRAFT, it helps the requester format the procurement request in plain English and flags any missing fields. In MANAGER_REVIEW, it runs an anomaly check — does the line item pricing deviate significantly from the last three approved invoices for this vendor? It outputs a structured flag object. The manager sees the flag and makes the decision. The model does not.
Every state transition is logged to a PostgreSQL table: state name, transition timestamp, actor identity, input payload hash, output payload hash. When the auditor asked for the purchase-order trail, we pulled the stored state snapshot and showed the chain from DRAFT to PO_GENERATION, with every approval attributed to a named user.
The audit passed.
Replayability as a Design Requirement

| 1 | workflow.add_node("draft", draft_node) | |
| 2 | workflow.add_node("review", review_node) | |
| 3 | ||
| 4 | # Classical deterministic routing | |
| 5 | workflow.add_edge("draft", "review") | ← ① |
| 6 | workflow.add_conditional_edges( | |
| 7 | "review", | |
| 8 | check_approval_state, | |
| 9 | {"approved": "po_gen", "rejected": "draft"} | ← ② |
| 10 | ) |
- ① Explicit transition immune to hallucination
- ② Routing logic handled by standard Python dict mapping
The strongest argument for deterministic routing is not compliance. It is replayability.
Because the routing logic lives in explicit Python and state is serialised to PostgreSQL at every transition, the workflow is fully replayable. We can take the state payload, graph version, and configuration snapshot from a historical run and replay them. Under those pinned inputs, the routing outcome is identical — not because LLM outputs are deterministic, but because the transition logic that acts on those outputs is. That is a provable property of the routing layer.
You cannot make this guarantee if the LLM is the central router. Model versions change. Temperature introduces variance. Context window positioning affects output. Two runs of the same prompt on the same model version may produce different routing decisions. In a consumer chatbot, that variance is tolerable. In a procurement system processing eight-figure annual spend, it is disqualifying.
LangGraph enforces the graph you define: nodes, edges, and transition functions are explicit code rather than model-generated routing. The compliance guarantee comes from encoding the required approval path in that graph, then testing and auditing it. This is the right primitive for enterprise agentic work — not because it’s clever, but because it mirrors how compliance-controlled workflows have always been designed. State machines are not a new idea. We’re applying them to AI-adjacent systems the way they should have been applied from the start.
Build the DAG First
Procurement teams and compliance officers have seen enough unbounded agent demos. They want to know what happens when the agent is wrong, how you detect it, and how you roll it back. “We’ll improve the prompt” is not an answer they will accept.
This approach carries a genuine upfront cost. Building explicit DAGs requires front-loaded domain modeling: process maps, defined approval thresholds, a clear taxonomy of states — all before the first line of code. Teams that skip this work sometimes reach for fully autonomous agents instead, which defers the modeling problem until it surfaces as an incident. That modeling effort isn’t unique to AI-adjacent systems; any responsible automation of a compliance-controlled workflow demands the same rigor. With a deterministic DAG, the work is visible and auditable from day one.
The architecture that passes these reviews is the same one engineers have used for critical workflow automation for decades: define the states, define the transitions, enforce the rules in code. The new ingredient is the LLM, injected as a narrow, specialised worker at the nodes where probabilistic extraction is actually needed.
Restrict agent freedom to guarantee outcomes. If you’re building for compliance, procurement, or any domain where a wrong decision has a paper trail, build the DAG first. Then ask where, specifically, an LLM makes the system better than a regex. The answer is almost always: parsing, flagging, and formatting. Not routing.
The engine is powerful. Build better rails.