
Escaping Context Collapse: An N-ary Tree Architecture for 100K-Word Generation
By Timothy Mo ·
Large context windows fail at generating cohesive text past 20,000 words due to context collapse. To reliably generate 100,000 words, developers must replace linear RAG with a hierarchical N-ary tree architecture and a centralized global state.
Escaping Context Collapse: An N-ary Tree Architecture for 100K-Word Generation
By Timothy Mo
At the 20,000-word mark — roughly 26,000 tokens — our generation pipeline started lying to itself.
We were building a cohesive 100,000-word technical manuscript at wGrow, and we ran it through the two obvious choices: GPT-4o (128k context window) and Claude 3.5 Sonnet (200k context window). Both failed — not spectacularly, but insidiously. Telemetry logged a 78% context degradation rate past that threshold: established technical variables were hallucinated into new definitions, narrative threads were silently abandoned, and stylistic register gradually normalized toward each model’s default alignment voice. Repetition penalties didn’t help. Linear chained RAG — feeding the last generated chapter as context for the next — made cascading drift worse, not better. The architecture that failed us is the one most teams ship first. What follows is what replaced it.
The 20,000-Word Context Collapse
The engineering assumption behind large context windows is seductive: if a model can read 200,000 tokens, it can write coherently across them. It can’t. That distinction matters more than most teams expect.
Context windows are a read-state solution. Attention mechanisms are computationally expensive and empirically lossy over long spans. Research into frontier model recall by position — the well-documented “lost in the middle” effect — shows that retrieval accuracy for facts placed in the middle of a long context degrades significantly relative to facts placed near the beginning or end. For generation tasks, the degradation compounds. The model isn’t passively reading; it’s writing new tokens while maintaining positional coherence across tens of thousands of prior tokens. The analogy holds intuitively: reading a 500-page document is a different cognitive operation than writing a coherent chapter 22 while holding every character decision from chapter 1 in working memory.
Our baseline testing confirmed this across three pipeline architectures:
- Zero-shot sequential generation — prompt with instructions, generate chapter by chapter.
- Linear chained RAG — inject the last 8,000 tokens of prior output as rolling context.
- Full-context injection — attempt to load all prior output within the model’s declared window.
All three degraded past 20,000 words. Zero-shot was worst: by word 15,000, the model had invented two new technical terms that directly contradicted established definitions from word 3,000. Linear RAG introduced stylistic drift — the prose at word 25,000 read like a different author, closer to the model’s default register than to the established manuscript voice. Full-context injection hit latency and cost ceilings and still hallucinated at 30,000 words, confirming that window size is not the binding constraint. Continuous generation requires external structural enforcement.
Establishing the Output Bible as the Global State
The first architectural decision: stop treating previously generated text as the source of continuity. Prior output is too large, too noisy, and too expensive to inject wholesale into every generation call. What the model needs is not the text it produced — it needs the state that text represents.
We introduced the Output Bible: a persistent, highly structured JSON object that acts as the single source of truth for the entire generation process. It lives outside session memory. It is injected as a system prompt to every downstream node. It contains no raw prose.
The schema divides into three immutable top-level blocks:
{
"metadata": {
"target_word_count": 100000,
"pacing_constraints": "...",
"stylistic_rules": {
"restricted_vocabulary": ["...", "..."],
"sentence_length_variance": "high",
"register": "technical-instructional"
}
},
"global_entities": {
"characters": {},
"core_variables": {},
"primary_arguments": {}
},
"macro_arc": {
"beginning": "...",
"middle": "...",
"end": "..."
}
}metadata encodes constraints that must not drift: word count targets per section, sentence complexity rules, vocabulary exclusion lists. If the Output Bible specifies British spellings and prohibits passive voice in technical sections, every node inherits those rules without re-prompting.
global_entities is the most critical block. Every named entity — a character, a technical variable, a recurring argument — is declared here with its canonical definition and current state. When a generation node at word 60,000 references a concept introduced at word 4,000, it does not re-read word 4,000. It reads the entity’s current state in the Output Bible. This is the mechanism that eliminates hallucination of previously established variables.
macro_arc encodes the overarching narrative trajectory in plain language — not chapter summaries (those live lower in the tree), but the single-sentence description of the journey from word 0 to word 100,000.
The immutability rule is non-negotiable: no terminal node — the prose-generating agents — can write back to the Output Bible. Only orchestrator nodes at Level 0 and Level 1 can update it, and only during their designated initialization phase. This is what stops a downstream hallucination from propagating into the global state mid-run. After generation begins, the Output Bible is append-only.
Structuring the N-Ary Tree
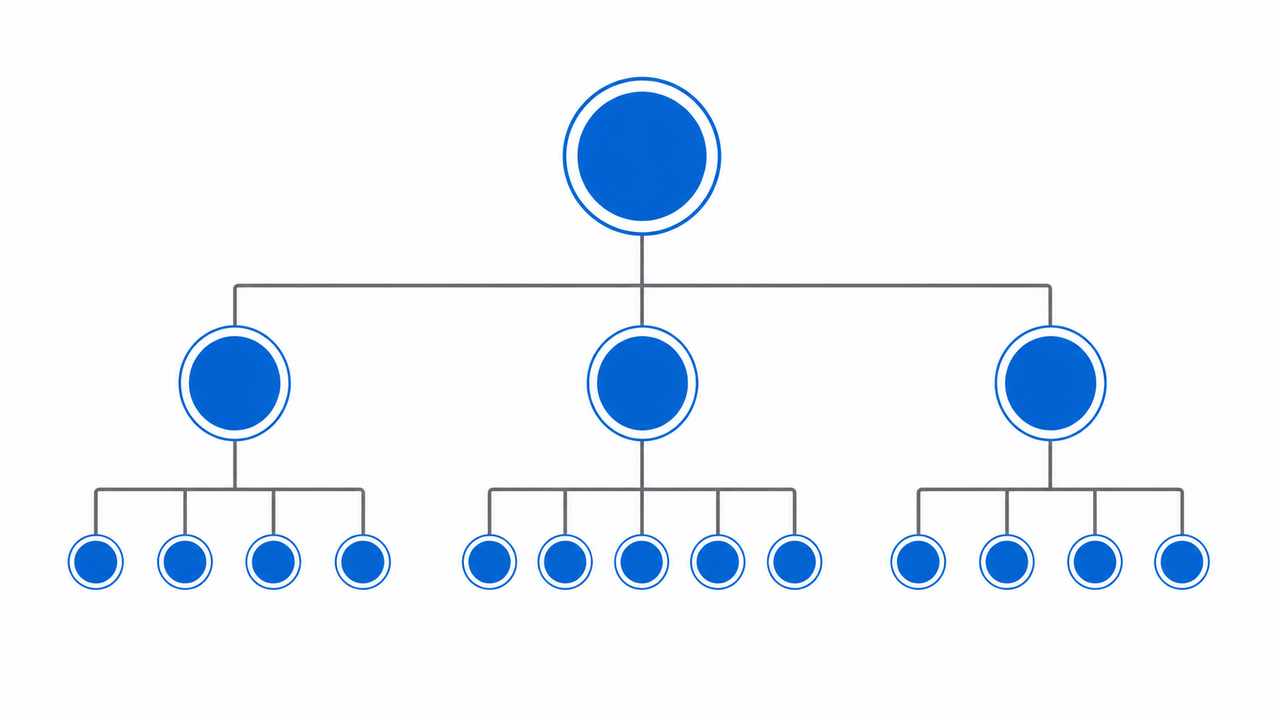
The binary tree framing common in agent architecture papers is an awkward fit for real content generation. Binary trees force two-child splits at every node; actual manuscripts have three-act structures, multi-chapter outlines, and chapters with variable beat counts. The better structure is a hierarchical N-ary tree, where each node spawns N children appropriate to its content requirements.
We organized the tree into four levels:
Level 0 — Root Node. A single node. It holds the global topic, initializes the Output Bible, and performs top-level structural synthesis. This is the only node with full planning authority. Frontier-class model assignment is worth it here — the synthesis requires strong logical coherence, not throughput.
Level 1 — Arc Nodes. The root spawns one child per major arc. For a three-act structure, that’s three Arc Nodes: Beginning, Middle, End. Each Arc Node receives the Output Bible and expands its arc into a discrete chapter list. Its output is not prose — it’s a structured arc definition that feeds Level 2.
Level 2 — Outline Nodes. Each Arc Node spawns N Outline Nodes, one per chapter. An Outline Node receives the Output Bible, its parent Arc definition, and its positional metadata (chapter index, target word count). It outputs a granular chapter plan: argument sequence, entities touched, expected word count, opening and closing beat summaries. Still no prose.
Level 3 — Beat Nodes. Each Outline Node spawns M Beat Nodes. A Beat is the smallest discrete generation unit — typically 300–800 words covering a single argument or narrative movement. Beat Nodes are the only nodes that generate prose. They receive the Output Bible, their parent chapter outline, and a tightly scoped beat instruction. They have no visibility into adjacent beats’ raw text; continuity comes exclusively from the Output Bible and their structural position in the tree.
That dependency isolation is the core engineering insight. Beat Node C3-B2 (Chapter 3, Beat 2) does not need to load the raw output of C1-B1 (Chapter 1, Beat 1). It needs the Output Bible, its chapter outline, and its beat instruction. The context window for any single generation call stays under 8,000 tokens regardless of total output produced. The N-ary tree decouples generation scale from context window size.
Tree traversal follows a strict top-down, layer-complete policy: the system does not begin expanding Level 2 until every Level 1 Arc Node is finalized and validated. It does not begin generating Level 3 Beat Nodes until every Level 2 Outline Node is locked. Structural drift propagating downward is the most expensive class of failure in a long-form pipeline, and layer-complete traversal is how you prevent it.
Layer-by-Layer Execution and Model Routing
Not every node needs a frontier model. This is where the architecture recovers its cost.
Level 0 and Level 1 handle complex logical synthesis — structural planning, arc definition, entity registration. These require strong reasoning and receive GPT-4o or Claude 3.5 Sonnet. Compute cost here is front-loaded and bounded: a small number of planning calls, each under 4,000 tokens. Across a full 100,000-word project, the cost at these two layers is negligible relative to generation volume.
Level 2 Outline Nodes perform constrained expansion — given the arc, produce a structured chapter plan. It’s a reasoning task, but a narrower one. In our testing, Claude 3.5 Haiku performs equivalently to Sonnet on structured output tasks here at roughly one-fifth the cost per token, saving approximately 60–70% of Level 2 compute with no measurable quality loss.
Level 3 Beat Nodes handle prose generation at scale, and this is where cost optimization matters most — Beat Nodes vastly outnumber planning nodes. A 100,000-word manuscript with 600-word beats means roughly 167 Beat Nodes. These are routed to the fastest and cheapest models that can hold the Output Bible’s stylistic constraints: GPT-4o-mini, Claude 3.5 Haiku, or a fine-tuned Llama 3.1 70B. The fine-tuning path carries real engineering overhead — dataset curation, training runs, serving infrastructure — and is only worth pursuing when off-the-shelf models consistently miss the stylistic fidelity mark.
The parallelization advantage is significant. Because Beat Nodes in the same chapter are structurally independent — they share the Output Bible and chapter outline, but not each other’s raw text — Beats 4, 5, and 6 of Chapter 3 can be generated simultaneously once the Chapter 3 Outline Node is locked. We saturated 8 parallel generation workers with no measurable output quality degradation. Wall-clock time for 100,000 words dropped from approximately 14 hours (sequential) to under 2.5 hours (parallel Beat execution) on identical infrastructure.
The routing rule fits in 20 lines of orchestration logic:
if node.level <= 1: assign frontier model
elif node.level == 2: assign mid-tier model
elif node.level == 3: assign fast/cheap modelNo dynamic routing heuristics. No model fallback chains. Predictable cost, predictable latency.
Cross-Session Continuity and Checkpointing

A 100,000-word generation run does not complete in a single compute session. Servers restart. API rate limits are hit. Network partitions happen. The architecture treats session failure as a first-class operational concern, not an edge case.
We implemented node-level checkpointing. Every completed Beat Node writes its output to durable storage immediately on completion, tagged with its full tree path (arc index, chapter index, beat index). The system maintains a lightweight completion manifest — a flat JSON file mapping each node’s tree path to its state: pending, in_progress, completed, or failed.
On session restart, the orchestrator traverses the tree top-down, reads the manifest, and resumes from the first pending or failed node. Because Beat Node outputs are isolated — each beat’s prose doesn’t depend on adjacent beats’ raw text — partial completion is clean. No need to re-generate validated beats or handle overlapping context from a mid-session drop.
State reconciliation handles mid-beat failures conservatively: if a session drops while a Beat Node is in_progress, the system treats it as failed on restart and re-generates from scratch. The compilation step reads exclusively from completed nodes; in_progress outputs are discarded. A 600-word beat is cheap to regenerate. Correctness matters more than avoiding a single repeat call.
The validation feedback loop before committing a Beat Node output runs three checks against the Output Bible:
- Do any entity references in the prose contradict their canonical definition in
global_entities? - Does the prose exceed or fall short of its target word count by more than 15%?
- Does the prose’s closing sentence set up the next beat’s opening context as specified in the chapter outline?
Failures at step 1 trigger an automatic retry with an explicit correction prompt. Failures at steps 2–3 are logged but don’t block commit — they’re flagged for the post-generation audit pass. The validation rules are deliberately narrow: they catch the highest-risk failure mode (entity contradiction) while avoiding false positives that would stall generation on stylistic edge cases. Keep the pipeline moving. Don’t put humans in the critical path.
The Structural Discipline Is the Point
The belief that large context windows solve long-form generation leads engineering teams into expensive dead ends. At sufficient scale, this is a systems problem, not a model capability problem.
The Output Bible solves the global state problem. The N-ary tree solves dependency isolation. Strict model routing controls cost. Layer-complete traversal prevents structural drift. Checkpointing handles session failures. Each component addresses a specific failure mode; none requires a next-generation foundational model. Together they mean treating probabilistic text generation as what it actually is: an unreliable compute primitive that needs deterministic scaffolding around it.
Worth being honest about the trade-offs. The Output Bible adds a meaningful design phase — entities and constraints must be thoughtfully specified before generation begins, and under-defined global state produces downstream problems that are genuinely difficult to diagnose mid-run. The tree structure assumes content can be decomposed into structurally independent beats; arguments requiring tight intra-chapter cross-referencing need either finer-grained beat design or additional inter-node context passing, at some cost to isolation. And the checkpointing and orchestration layer is real engineering overhead compared to a simple sequential prompt chain.
Below 20,000 words, a well-structured sequential pipeline with strong initial prompting is usually sufficient and far simpler to operate. These trade-offs earn their keep at 100,000 words.
Engineering teams don’t need to wait for 1M-token context windows. They need to stop loading raw text into context and start building structured state management outside the model. The N-ary tree scales to any length target — 100K words, 500K words, full book length — because generation scale is a function of tree depth and node count, not context window size.
The hard part isn’t the model. It’s the scaffold.